

이전 part1에서는 프로젝트 개요 및 데이터 수집을 진행했다. 이번 파트에서는 Lambda 함수와 Glue를 사용하여 데이터 처리를 구현하는 것에 초점을 맞춘다.
Architecture
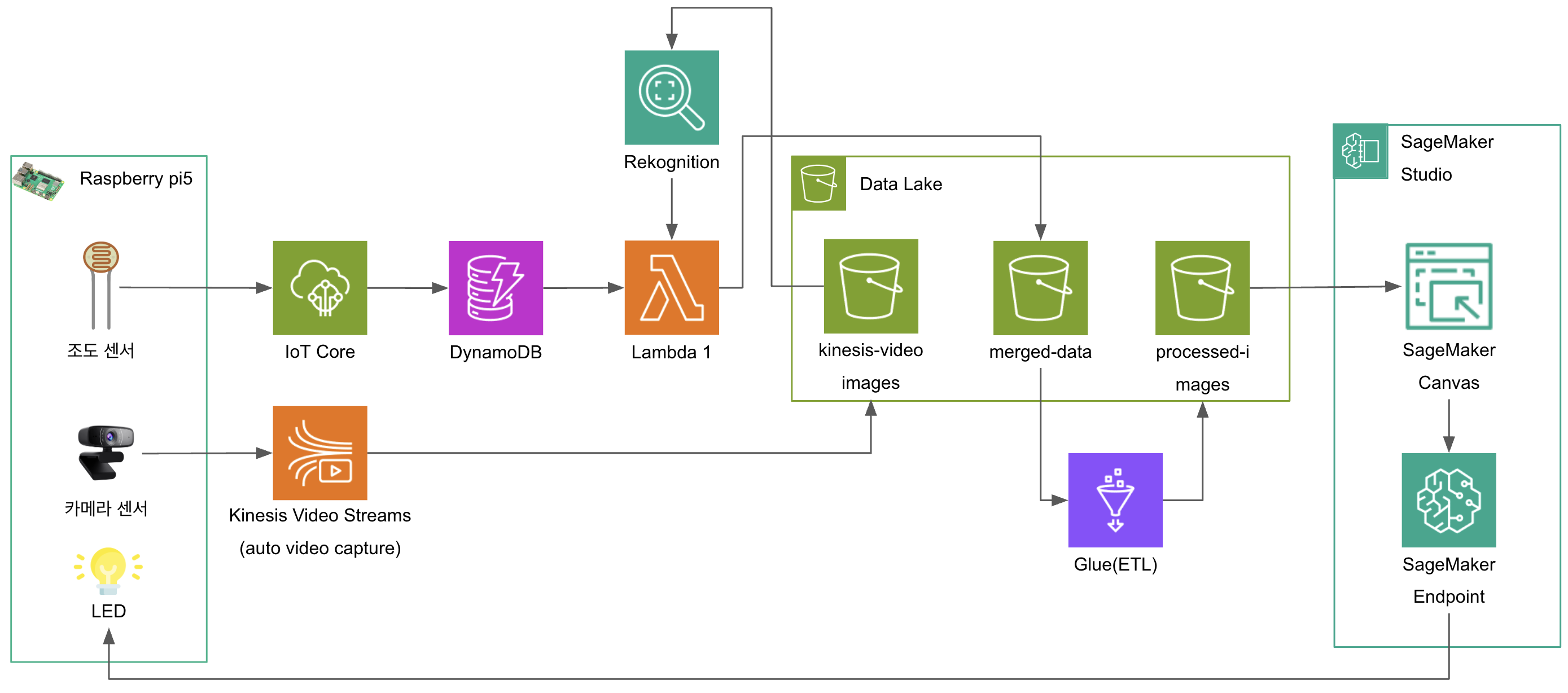
이번 파트의 핵심
- Lambda 함수 개발 및 데이터 병합
- AWS Glue ETL을 통한 데이터 통합 및 전처리
3. Lambda 함수 개발 및 데이터 병합
- 함수 생성
- 새로작성
- 함수 이름 지정
- 런타임 : Python 3.9
- 트리거 추가
- S3 버킷에 새 이미지 업로드 시 Lambda 함수 자동 호출
- Lambda 코드 작성
import boto3
import csv
import json
import urllib.parse
import os
from datetime import datetime, timedelta
from io import BytesIO, StringIO
from PIL import Image
import decimal
# AWS 클라이언트 설정
s3_client = boto3.client("s3")
rekognition_client = boto3.client("rekognition")
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('LightSensorData')
# Rekognition Collection ID
COLLECTION_ID = "face-detect"
# S3 저장소 정보
S3_BUCKET_NAME = "[Your S3 Bucket Name]"
S3_PROCESSED_PREFIX = "processed-images/" # 최종 CSV 저장 위치
# Helper class for DynamoDB decimal conversion
class DecimalEncoder(json.JSONEncoder):
def default(self, o):
if isinstance(o, decimal.Decimal):
return float(o) if o % 1 else int(o)
return super(DecimalEncoder, self).default(o)
def get_closest_light_data(target_time):
""" DynamoDB에서 대상 시간과 가장 가까운 조도 데이터 조회 """
try:
# 타임스탬프가 문자열이 아니면 ISO 포맷으로 변환
if not isinstance(target_time, str):
target_time = target_time.isoformat()
# 대상 시간 전후 30초 범위의 데이터 조회를 위한 시간 계산
# UTC 타임존 정보가 있는 경우 제거하여 naive datetime으로 변환
if '+00:00' in target_time or 'Z' in target_time:
target_dt = datetime.fromisoformat(target_time.replace('Z', '+00:00'))
# offset-aware를 offset-naive로 변환
target_dt = target_dt.replace(tzinfo=None)
else:
target_dt = datetime.fromisoformat(target_time)
start_time = (target_dt - timedelta(seconds=30)).isoformat()
end_time = (target_dt + timedelta(seconds=30)).isoformat()
print(f"🔍 다음 시간 범위의 조도 데이터 검색: {start_time} ~ {end_time}")
# DynamoDB 쿼리 - 대상 시간 범위의 데이터 조회
response = table.scan(
FilterExpression="#ts BETWEEN :start_time AND :end_time",
ExpressionAttributeNames={
'#ts': 'timestamp' # 예약어 timestamp에 대한 별칭 사용
},
ExpressionAttributeValues={
':start_time': start_time,
':end_time': end_time
}
)
items = response.get('Items', [])
# 결과가 없으면 가장 최근 데이터 1개 조회
if not items:
print("⚠ 대상 시간 범위 내 데이터 없음, 최근 데이터 조회")
# 최근 10개 항목 스캔하여 가장 최신 항목 선택
response = table.scan(
Limit=10,
ProjectionExpression="lightValue, #ts",
ExpressionAttributeNames={'#ts': 'timestamp'}
)
items = sorted(response.get('Items', []),
key=lambda x: x['timestamp'],
reverse=True)[:1]
if not items:
print("❌ 조도 데이터를 찾을 수 없음, 기본값 사용")
return 0, "N/A"
print(f"⚠ 가장 최근 데이터 사용 ({items[0]['timestamp']})")
return items[0]['lightValue'], items[0]['timestamp']
# 타임스탬프와 가장 가까운 항목 찾기
closest_item = min(items,
key=lambda x: abs(datetime.fromisoformat(x['timestamp']) - target_dt))
time_diff = abs(datetime.fromisoformat(closest_item['timestamp']) - target_dt).total_seconds()
print(f"✅ 가장 가까운 조도 데이터 찾음: {closest_item['timestamp']} (시간차: {time_diff:.1f}초)")
return closest_item['lightValue'], closest_item['timestamp']
except Exception as e:
print(f"❌ DynamoDB에서 조도 데이터 조회 중 오류: {e}")
return 0, "N/A"
def convert_to_baseline_jpeg(image_bytes):
""" 이미지를 Rekognition에서 지원하는 Baseline JPEG로 변환 """
try:
img = Image.open(BytesIO(image_bytes))
if img.format != "JPEG":
print("⚠ 이미지가 JPEG 형식이 아님 → 변환 중...")
output = BytesIO()
img.convert("RGB").save(output, format="JPEG", quality=95)
return output.getvalue()
return image_bytes
except Exception as e:
print(f"❌ 이미지 변환 실패: {e}")
return None
def save_results_to_s3(image_key, label, light_value, light_timestamp):
""" Rekognition & 조도 데이터 병합 후 CSV 파일로 만들어 S3에 저장 """
try:
csv_buffer = StringIO()
csv_writer = csv.writer(csv_buffer)
# CSV 헤더 추가
csv_writer.writerow(["image name", "s3 path", "yoo", "light-value", "light-timestamp"])
# S3 경로 포함하여 결과 추가
image_s3_path = f"s3://{S3_BUCKET_NAME}/{image_key}"
image_name = os.path.splitext(image_key.split("/")[-1])[0] # 확장자 제거
# Decimal 타입인 경우 변환
if isinstance(light_value, decimal.Decimal):
light_value = float(light_value)
csv_writer.writerow([image_name, image_s3_path, label, light_value, light_timestamp])
# S3 저장 경로
csv_filename = f"{image_name}.csv" # 확장자 제거된 파일명 사용
csv_s3_key = f"{S3_PROCESSED_PREFIX}{csv_filename}"
# CSV 파일을 S3에 업로드
s3_client.put_object(
Bucket=S3_BUCKET_NAME,
Key=csv_s3_key,
Body=csv_buffer.getvalue(),
ContentType="text/csv",
)
print(f"✅ CSV 저장 완료: {csv_s3_key}")
except Exception as e:
print(f"❌ CSV 저장 실패: {e}")
def lambda_handler(event, context):
"""S3에 업로드된 이미지를 Rekognition으로 분석 + 이미지 타임스탬프와 가장 가까운 조도 데이터를 찾아 CSV로 저장"""
print(f"📥 Lambda Received Event: {json.dumps(event, indent=4)}")
# 'Records' 키가 없는 경우 처리
if 'Records' not in event:
print("⚠ 'Records' 키가 없는 이벤트입니다. 테스트 또는 직접 호출된 이벤트일 수 있습니다.")
return {
"statusCode": 400,
"body": "Invalid event structure. Expected S3 event with 'Records' key."
}
for record in event["Records"]:
bucket_name = record["s3"]["bucket"]["name"]
image_key = urllib.parse.unquote_plus(record["s3"]["object"]["key"])
# 이미지 파일만 처리하도록 필터 추가
if not image_key.lower().endswith((".jpg", ".jpeg", ".png")):
print(f"⚠ 이미지 파일이 아님, Rekognition 분석 생략: {image_key}")
return {"statusCode": 200, "body": "Skipped non-image file"}
print(f"📂 감지된 파일: s3://{bucket_name}/{image_key}")
try:
# S3 객체 메타데이터에서 마지막 수정 시간 가져오기
response = s3_client.head_object(Bucket=bucket_name, Key=image_key)
last_modified = response['LastModified']
print(f"📅 이미지 업로드 시간: {last_modified}")
# 이미지 업로드 시간과 가장 가까운 조도 데이터 가져오기
light_value, light_timestamp = get_closest_light_data(last_modified)
print(f"💡 조도 센서 값 확인: {light_value}, 기록 시간: {light_timestamp}")
# S3에서 이미지 다운로드
response = s3_client.get_object(Bucket=bucket_name, Key=image_key)
image_bytes = response["Body"].read()
# 이미지가 JPEG가 아니라면 변환
processed_image = convert_to_baseline_jpeg(image_bytes)
if processed_image is None:
return {"statusCode": 500, "body": "Image conversion failed"}
# Rekognition으로 얼굴 검색
rekognition_response = rekognition_client.search_faces_by_image(
CollectionId=COLLECTION_ID,
Image={"Bytes": processed_image},
MaxFaces=1,
FaceMatchThreshold=95,
)
is_yoo_detected = len(rekognition_response["FaceMatches"]) > 0
label = "Y" if is_yoo_detected else "N"
print(f"✅ Rekognition 결과: {label}")
# 결과를 CSV로 저장
save_results_to_s3(image_key, label, light_value, light_timestamp)
except rekognition_client.exceptions.InvalidParameterException as e:
# 얼굴 검색 실패 (얼굴이 이미지에 없는 경우)
print(f"⚠ Rekognition 얼굴 검색 실패 (얼굴 없음): {e}")
# 가장 최근 조도 데이터 가져오기
light_value, light_timestamp = get_closest_light_data(datetime.utcnow())
# 얼굴이 없으므로 "N" 라벨로 저장
save_results_to_s3(image_key, "N", light_value, light_timestamp)
except Exception as e:
print(f"❌ 처리 중 오류 발생: {e}")
return {"statusCode": 500, "body": json.dumps({"error": str(e)})}
return {"statusCode": 200, "body": json.dumps({"message": "Processing complete"})}
-
- 시간 기반 조도 데이터 조회 함수
- 이미지 업로드 시간(LastModified) 전후 30초 범위 내 DynamoDB에서 가장 가까운 조도 데이터 검색
- timestamp 예약어 처리를 위한 ExpressionAttributeNames 사용
- 데이터가 없을 경우 가장 최근 조도 데이터 사용
- 속성: lightValue (Decimal 타입), ttl (24시간 자동 만료)
- 예약어 처리를 위한 ExpressionAttributeNames 사용
- 이미지가 JPEG 형식이 아닌 경우 JPEG로 변환 함수
- 데이터 병합 및 CSV 형식으로 S3에 저장하는 함수
- 데이터 병합 결과를 CSV 파일로 변환하고
- S3의 processed-images/ 경로에 저장
- Lambda 핸들러 함수
- S3에서 이미지 가져오기
- JPEG 형식의 이미지가 아니라면 변환함수 실행
- Rekognition으로 얼굴 인식
- Lambda 함수에서 Rekognition의 search_faces_by_image API 호출
- 사전에 등록된 유재석 얼굴 컬렉션(face-detect)과 비교 95% 이상의 일치도를 기준으로 유재석 여부 판단 검색 결과에 FaceMatches가 있으면 "Y", 없으면 "N"으로 레이블
- 데이터 병합 및 CSV 형식으로 S3에 저장하는 함수 실행
- 시간 기반 조도 데이터 조회 함수
- 결과: Lambda 함수를 통해 총 405개의 데이터 수집 완료
- 저조도 + 유재석 감지 케이스
- 저조도 + 유재석 미감지 케이스
- 정상 조도 + 유재석 감지 케이스
- 정상 조도 + 유재석 미감지 케이스
4. AWS Glue ETL을 통한 데이터 통합 및 전처리
- ETL 작업 개발
- Script Editor를 통해 Script 생성
- Spark 스크립트 작성:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame
from pyspark.sql.functions import lit, current_timestamp, col, when
# 초기화
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
# 소스 데이터 경로와 대상 경로 설정
source_path = "[Your S3 Bucket Name]/processed-images/"
target_path = "[Your S3 Bucket Name]/merged-data/"
# 모든 CSV 파일을 읽어 Dynamic Frame으로 변환
datasource = glueContext.create_dynamic_frame.from_options(
connection_type="s3",
connection_options={
"paths": [source_path],
"recurse": True,
"groupFiles": "inPartition",
"groupSize": 1048576 # 1MB 기준으로 그룹화
},
format="csv",
format_options={
"withHeader": True,
"separator": ","
}
)
print(f"원본 데이터 건수: {datasource.count()}")
print("스키마 정보:")
datasource.printSchema()
# DataFrame으로 변환
df = datasource.toDF()
# 중복 제거 (동일한 이미지가 여러 번 처리된 경우)
distinct_data = df.dropDuplicates(["image name"])
# 저조도 판별 열 추가 (예: 50% 미만을 저조도로 정의)
df_with_flags = distinct_data.withColumn(
"is_low_light",
when(col("`light-value`") < 50, True).otherwise(False)
)
# 저조도+유재석 감지 열 추가
df_with_target = df_with_flags.withColumn(
"is_target_in_low_light",
when((col("is_low_light") == True) & (col("yoo") == "Y"), True).otherwise(False)
)
# 처리 시간 추가
df_final = df_with_target.withColumn("processed_at", current_timestamp())
# 다시 DynamicFrame으로 변환
processed_data = DynamicFrame.fromDF(df_final, glueContext, "processed_data")
# 현재 시간 기반 파일명 생성
current_time = current_timestamp().cast("string")
timestamp = current_time._jc.toString().replace(" ", "_").replace(":", "-").replace(".", "-")
output_filename = f"merged_light_sensor_data_{timestamp}"
# 단일 파일로 저장
processed_data_repartitioned = processed_data.toDF().repartition(1)
processed_data_single = DynamicFrame.fromDF(processed_data_repartitioned, glueContext, "processed_data_single")
# 데이터 저장
glueContext.write_dynamic_frame.from_options(
frame=processed_data_single,
connection_type="s3",
connection_options={
"path": target_path,
"partitionKeys": []
},
format="csv",
format_options={
"writeHeader": True,
"separator": ","
}
)
print(f"처리 완료: {processed_data.count()} 건의 데이터가 {target_path} 경로에 저장되었습니다.")
job.commit()- 핵심 데이터 변환 작업:
- 중복 데이터 제거: dropDuplicates() 함수로 동일 이미지 처리 기록 중복 제거
- 저조도 판별 변수 생성: 조도 값 50 미만을 기준으로 'is_low_light' 파생 변수 생성
- 목표 변수 생성: 저조도 + 유재석 감지 조합으로 'is_target_in_low_light' 변수 생성
- 처리 시간 기록: 데이터 처리 시점을 'processed_at' 열에 저장
- 총 405개의 CSV 파일을 하나의 데이터셋으로 병합하여 [Your S3 Bucket Name]/merged-data/ 에 저장
- IAM Role 연결
- 다음 권한 정책이 들어가 있는 IAM Role 연결
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::[Your S3 Bucket Name]/*",
"arn:aws:s3:::[Your S3 Bucket Name]"
]
}
]
}